What is High Availability?
In simple terms, High Availability (HA) is the ability of a service to continue operating despite failures within its environment. You can achieve HA by designing a system with no single point of failure. In a high availability system, workloads are distributed across a cluster of server nodes. If one server node fails, the workloads running on it automatically move to other servers. It helps ensure that critical applications keep running even when problems occur in other parts of the system.
The main goal of High Availability is to minimize the impact that downtime and outages have on an organization’s business processes.
A common misconception of High Availability is that an IT system will be available 24/7. Even at the highest level of HA, an organization should still prepare for a small percentage of planned or unplanned downtime, which an SLA usually defines with “Five Nines” being the highest level of Availability.
How much High Availability do you need?
If you were to ask people how much their IT systems should be protected against downtime, the obvious reply would be 24/7, always available; however, this is incredibly challenging and costly to achieve.
Before any organization can consider a strategy for High Availability, a proper business impact analysis is needed to identify critical business processes and the risk related to planned and unplanned downtime of the interconnected IT systems.
Although some organizations may require the highest availability level, many do not. Additionally, not all IT services are business critical; therefore, it may be more acceptable and economical for some organizations to have a High Availability SLA of 99% vs. 99.999%.
📓 A simple example could be a supermarket that requires its online payment system to be available at the highest level of Availability. The impact of not having this service available can result in loss to the business because customers will not be able to make any purchases if they do not have cash on them. The same supermarket will, however, be less impacted if the print system in the back office were to go offline for a few minutes due to planned or unplanned downtime.
Determine High Availability Requirements with a Business Impact Analysis (BIA)
Before deciding on a High Availability strategy, an organization should carry out a business impact analysis (BIA) to determine the severity of the impact that IT-related outages and downtime have on critical business processes and to identify requirements needed to ensure the continuity of operations.
A business impact analysis may differ from organization to organization but usually covers the following:
-
Identifies critical business processes.
-
Calculates a measurable risk of loss due to IT outages and downtime.
-
Considers essential business functions, people, and business dependencies.
-
It is based on data gathered via BIA interviews with employees.
Ultimately, the BIA will allow the organization to see how a business would be affected if you took business processes away during IT systems outages/downtime. It helps the organization determine which business processes are the most critical for continued operation and assists in creating a recovery plan.
Key Recovery Objectives
When considering High Availability, there are two key parameters that define how long your organization can afford to be offline and how much data loss it can tolerate. These parameters are the Recovery Time Objective (RTO) and Recovery Point Objective (RPO).
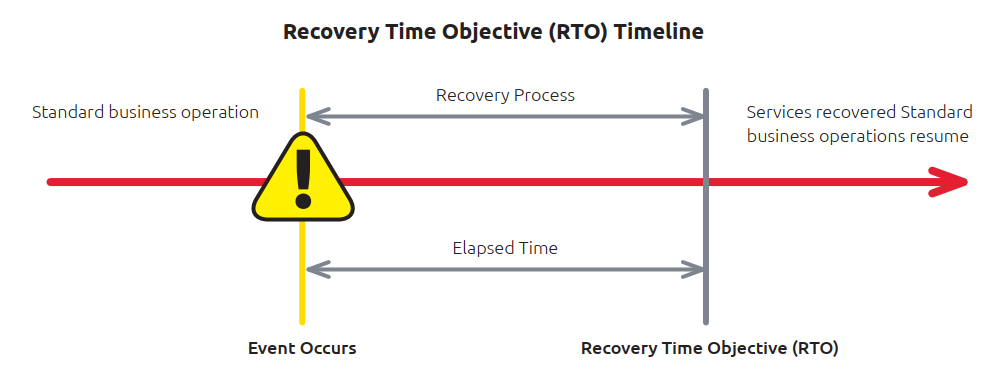
Recovery Time Objective (RTO) is defined as the maximum length of time it takes for an IT system, set of applications etc. to recover from downtime (planned, unplanned or a disaster) and resume standard business operations.
RTO timelines are decided amid Business Impact Analysis (BIA) during business and IT continuity planning.
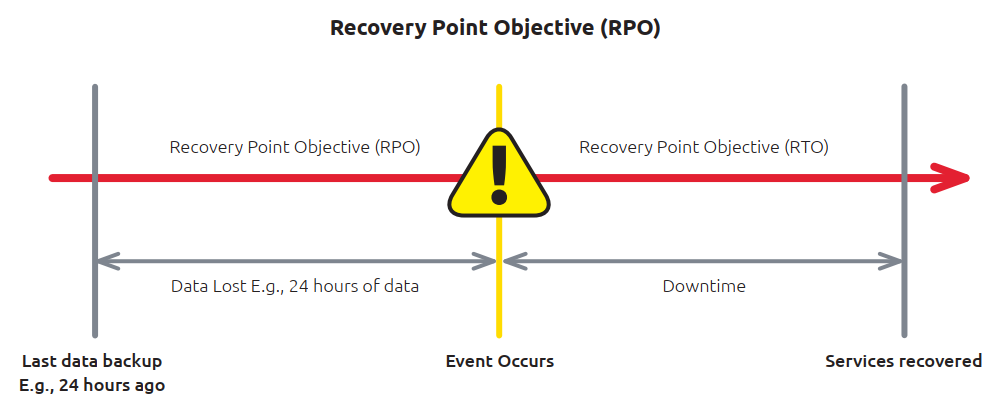
Recovery Point Objective (RPO) is a measure of how often you back up. Can you afford to lose a certain number of minutes, hours, or days of data updates if disaster strikes between backups? RPO indicates how recent the restored data will be.
For example, if you experience a failure now and your last full data backup was 24 hours ago, the RPO is 24 hours. Essentially, RPO has to do with the frequency of backups, while RTO refers to recovery time.
How to Measure High Availability
High Availability is measured in the percentage of time that a service is available to users, often referenced by the number of nine’s in the digits. Five Nines is used to describe an IT system’s continuity with 99.999 uptime. In other words, the IT system or service is only unavailable for 5.39 minutes throughout the year for planned or unplanned downtime.

Achieving five-nines of High Availability over time is incredibly challenging. It is expensive due to the running costs of the physical hardware infrastructure and software components, and additional components add to complexity and risk. For many services or networks, three or four nines would be more effective and justified regarding the resources and cost involved.