Was ist Hochverfügbarkeit?
Einfach ausgedrückt ist Hochverfügbarkeit (HA) die Fähigkeit eines Dienstes, trotz Ausfällen in seiner Umgebung weiter zu funktionierenSie können Hochverfügbarkeit erreichen, indem Sie ein System ohne Single Point of Failure entwerfen. In einem hochverfügbaren System werden die Workloads auf einen Cluster von Serverknoten verteilt. Wenn ein Serverknoten ausfällt, werden die darauf ausgeführten Workloads automatisch auf andere Server verlagert. Dies trägt dazu bei, dass kritische Anwendungen auch dann weiterlaufen, wenn in anderen Teilen des Systems Probleme auftreten.
Das Hauptziel von Hochverfügbarkeit ist es, die Auswirkungen von Ausfallzeiten und Störungen minimieren auf die Geschäftsprozesse einer Organisation haben.
Ein gängiges Missverständnis von Hochverfügbarkeit ist, dass ein IT-System rund um die Uhr verfügbar ist. Selbst bei höchster HA-Stufe sollte ein Unternehmen dennoch auf einen geringen Prozentsatz geplanter oder ungeplanter Ausfallzeiten vorbereitet sein, die in einem SLA in der Regel mit „Fünf Neunen“ als höchster Verfügbarkeitsstufe definiert werden.
Wie viel Hochverfügbarkeit benötigen Sie?
Wenn man Menschen fragen würde, inwieweit ihre IT-Systeme vor Ausfallzeiten geschützt sein sollten, wäre die offensichtliche Antwort „rund um die Uhr, immer verfügbar“. Dies ist jedoch äußerst anspruchsvoll und mit hohen Kosten verbunden.
Bevor eine Organisation eine Strategie für Hochverfügbarkeit in Betracht ziehen kann, ist eine angemessene Auswirkungsanalyse auf das Geschäft ist erforderlich, um kritische Geschäftsprozesse und die Risiken im Zusammenhang mit geplanten und ungeplanten Ausfallzeiten der miteinander verbundenen IT-Systeme zu identifizieren.
Obwohl einige Organisationen möglicherweise die höchste Verfügbarkeitsstufe benötigen, ist dies bei vielen nicht der Fall. Darüber hinaus Nicht alle IT-Dienste sind geschäftskritisch.Daher kann es für einige Unternehmen akzeptabler und wirtschaftlicher sein, ein SLA mit einer Hochverfügbarkeit von 99 % anstelle von 99,999 % zu haben.
📓 Ein einfaches Beispiel wäre ein Supermarkt, der von seinem Online-Zahlungssystem ein Höchstmaß an Verfügbarkeit verlangt. Wenn dieser Service nicht verfügbar ist, kann dies zu Verlusten für das Unternehmen führen, da Kunden ohne Bargeld keine Einkäufe tätigen können. Der gleiche Supermarkt wäre jedoch weniger beeinträchtigt, wenn das Drucksystem im Backoffice aufgrund einer geplanten oder ungeplanten Ausfallzeit für einige Minuten offline gehen würde.
Ermitteln Sie die Anforderungen an die Hochverfügbarkeit mithilfe einer Business Impact Analysis (BIA).
Bevor eine Organisation sich für eine Hochverfügbarkeitsstrategie entscheidet, sollte sie eine Business Impact Analysis (BIA) durchführen, um die Schwere der Auswirkungen von IT-Ausfällen und Ausfallzeiten auf kritische Geschäftsprozesse zu ermitteln und die Anforderungen zu identifizieren, die zur Gewährleistung der Betriebskontinuität erforderlich sind.
A Auswirkungsanalyse auf das Geschäft kann sich von Organisation zu Organisation unterscheiden, umfasst jedoch in der Regel Folgendes:
-
Identifiziert kritische Geschäftsprozesse.
-
Berechnet ein messbares Verlustrisiko aufgrund von IT-Ausfällen und Ausfallzeiten.
-
Berücksichtigt wesentliche Geschäftsfunktionen, Personen und geschäftliche Abhängigkeiten.
-
Es basiert auf Daten, die durch BIA-Interviews mit Mitarbeitern erhoben wurden.
Letztendlich ermöglicht die BIA dem Unternehmen zu erkennen, wie sich die Unterbrechung von Geschäftsprozessen während Ausfällen oder Ausfallzeiten von IT-Systemen auf das Geschäft auswirken würde. Sie unterstützt das Unternehmen dabei, zu ermitteln, welche Geschäftsprozesse für den fortlaufenden Betrieb am wichtigsten sind, und hilft bei der Erstellung eines Wiederherstellungsplans.
Wichtige Ziele der Wiederherstellung
Bei der Betrachtung von Hochverfügbarkeit sind folgende Aspekte zu berücksichtigen: zwei Schlüsselparameter die festlegen, wie lange Ihr Unternehmen es sich leisten kann, offline zu sein, und wie viel Datenverlust es tolerieren kann. Diese Parameter sind das Recovery Time Objective (RTO) und das Recovery Point Objective (RPO).
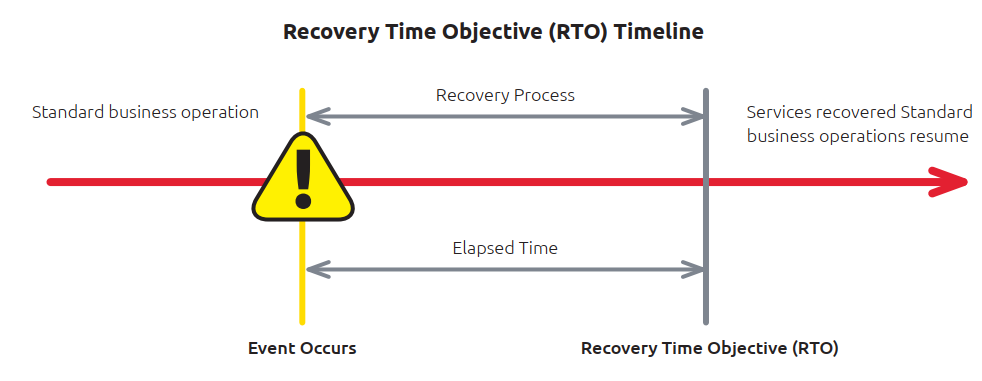
Wiederherstellungszeit (Recovery Time Objective, RTO) wird definiert als die maximale Zeitspanne, die ein IT-System, eine Reihe von Anwendungen usw. benötigt, um sich von einer Ausfallzeit (geplant, ungeplant oder aufgrund einer Katastrophe) zu erholen und den normalen Geschäftsbetrieb wieder aufzunehmen.
Die RTO-Fristen werden im Rahmen einer Business Impact Analysis (BIA) während der Geschäfts- und IT-Kontinuitätsplanung festgelegt.
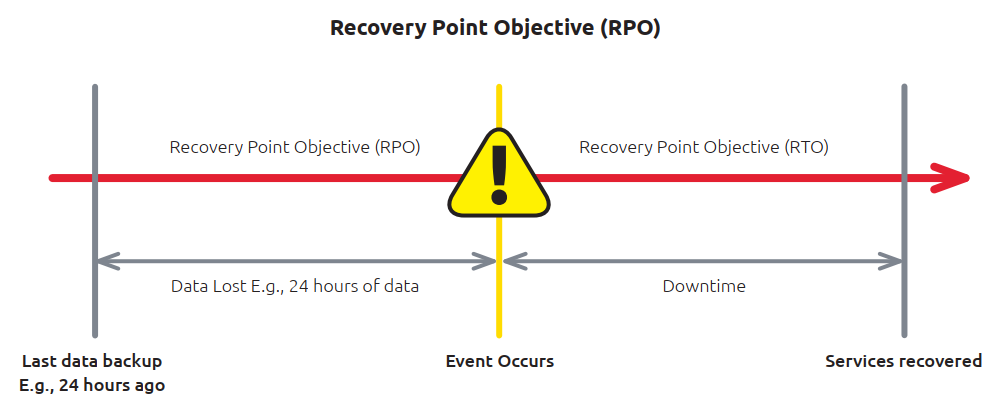
Wiederherstellungszeitpunkt (Recovery Point Objective, RPO) ist ein Maß dafür, wie oft Sie Backups erstellen. Können Sie es sich leisten, eine bestimmte Anzahl von Minuten, Stunden oder Tagen an Datenaktualisierungen zu verlieren, falls zwischen den Backups ein Notfall eintritt? RPO gibt an, wie aktuell die wiederhergestellten Daten sein werden.
Wenn beispielsweise derzeit ein Ausfall auftritt und die letzte vollständige Datensicherung vor 24 Stunden durchgeführt wurde, beträgt das RPO 24 Stunden. Im Wesentlichen bezieht sich das RPO auf die Häufigkeit der Sicherungen, während das RTO die Wiederherstellungszeit bezeichnet.
Wie man Hochverfügbarkeit misst
Hochverfügbarkeit wird anhand des Prozentsatzes der Zeit gemessen, in der ein Dienst für Benutzer verfügbar ist, häufig angegeben durch die Anzahl der Neunen in den Ziffern. Fünf Neuner wird verwendet, um die Eigenschaften eines IT-Systems zu beschreiben. Kontinuität mit einer Verfügbarkeit von 99,999 %Mit anderen Worten: Das IT-System oder der IT-Dienst ist aufgrund geplanter oder ungeplanter Ausfallzeiten nur 5,39 Minuten im gesamten Jahr nicht verfügbar.

Die Erreichung einer Hochverfügbarkeit von 99,999 % über einen längeren Zeitraum stellt eine erhebliche Herausforderung dar.Aufgrund der laufenden Kosten für die physische Hardware-Infrastruktur und Softwarekomponenten ist dies eine kostspielige Angelegenheit, und zusätzliche Komponenten erhöhen die Komplexität und das Risiko. Für viele Dienste oder Netzwerke wären drei oder vier Neuner hinsichtlich der erforderlichen Ressourcen und Kosten effektiver und angemessener.